srt / vtt / ass 字幕格式
SRT(SubRip Subtitle)、 VTT(WebVTT)、ASS(Advanced SubStation Alpha) 是3种非常常见的字幕格式。下面详细介绍每种字幕格式及其属性和设置。
SRT 字幕格式
SRT 是一种简单且广泛使用的字幕格式,后缀是.srt, 尤其在视频播放器、字幕编辑器中非常流行。其基本结构包括字幕编号、时间戳、字幕文本,字幕属性无法通过 SRT 直接定义(例如颜色、字体),通常依赖播放器的默认设置或外部样式文件来控制。
SRT 格式结构
SRT 文件中的每个字幕块按以下格式排列:
- 字幕编号(逐行递增)
- 时间戳(显示开始时间和结束时间,精确到毫秒)
- 字幕内容(可以包含多行文本)
- 一个空行(用于分隔字幕块)
SRT 示例
1
00:00:01,000 --> 00:00:04,000
你好啊我的朋友!
2
00:00:05,000 --> 00:00:08,000
今天天气不错,你觉得呢.
详细说明
字幕编号:每个字幕块都有唯一的编号,按顺序递增。编号从 1 开始,必须是整数。
时间戳:格式为 HH:MM:SS,mmm,其中 HH 是小时,MM 是分钟,SS 是秒,mmm 是毫秒。时间戳由两个时间组成,用 --> 分隔,该符号两侧各有一个空格,表示字幕的开始和结束时间。
- 示例:
00:00:01,000 --> 00:00:04,000
字幕内容:字幕文本可以包含一行或多行,显示在视频上。SRT 不支持格式化文本,如颜色、字体大小等。这些必须通过播放器设置或额外的样式文件定义。
SRT 格式限制
- 不支持文本格式化:不能直接设置颜色、字体等,需要播放器或其他工具进行样式调整。
VTT 字幕格式
WebVTT(Web Video Text Tracks)是用于 HTML5 视频元素的字幕格式,专为网络视频设计。它比 SRT 格式功能更强大,支持样式、注释、多语言、位置信息等属性,字幕文件格式后缀是.vtt。但它不可直接嵌入视频,必须在html的 <video> 中引用
VTT 格式结构
VTT 文件类似于 SRT,但带有更多的功能。VTT 文件以 WEBVTT后接1个空行开头,并且使用 .点符号而不是 , 来分隔秒和毫秒。
VTT 示例
WEBVTT
1
00:00:01.000 --> 00:00:04.000
你好啊, <b>朋友们!</b>
2
00:00:05.000 --> 00:00:08.000
今天的雨 <i>非常非常大啊</i>.
详细说明
WEBVTT 声明:所有 VTT 文件必须以 WEBVTT 开头,声明其文件格式。
字幕编号:字幕编号是可选的,不像 SRT 格式中是必需的。它的作用是区分每段字幕的顺序,但在 VTT 中可以省略。
时间戳:格式为 HH:MM:SS.mmm,其中 HH 是小时,MM 是分钟,SS 是秒,mmm 是毫秒。使用 .英文句号点分隔秒和毫秒,而不是 ,。时间戳由两个时间组成,用 --> 分隔,同样两侧各有一个空格。
- 示例:
00:00:01.000 --> 00:00:04.000
字幕内容:字幕文本可以包含 HTML 标签,用于格式化文本,如加粗(<b>)、斜体(<i>)、下划线(<u>)等。
VTT 支持的其他功能
样式(CSS):
- VTT 支持通过 CSS 进行文本样式的调整,如颜色、字体大小、位置等。可以在 HTML 中通过
<style> 标签或外部 CSS 文件定义样式。 - 示例:
<c.red>你好啊朋友们!</c>
在 HTML 中定义 .red { color: red; },则 Hello, world! 将以红色显示。
位置信息:
注释:
- VTT 支持在文件中添加注释,注释以
NOTE 开头。 - 示例:
NOTE 这行是注释,将不会显示.
多语言支持:
- VTT 可以通过元数据或 HTML5 的
<track> 标签来支持多语言字幕。
VTT 格式的优势
- 文本格式化:支持 HTML 标签进行简单的文本格式化,如加粗、斜体等。
- 样式和定位:通过 CSS 可以设置字幕的样式和位置。
- 注释和元数据:支持添加注释信息,不影响字幕显示。
- 网络兼容性:专为 HTML5 视频设计,适合 Web 环境。
SRT 与 VTT 的对比
| 特性 | SRT | VTT |
|---|
| 文件头 | 无 | WEBVTT后接1个空行 |
| 时间戳格式 | HH:MM:SS,mmm,英文逗号分隔秒和毫秒 | HH:MM:SS.mmm英文句号分割秒和毫秒 |
| 支持文本格式化 | 不支持 | 支持 HTML 标签,如 <b>、<i> |
| 字幕编号 | 必须有 | 可选 |
| 样式和位置支持 | 依赖播放器或外部样式文件 | 内置 CSS 样式支持,支持位置信息 |
| 注释 | 不支持 | 支持 NOTE 注释 |
| 支持的高级功能 | 仅基础字幕功能 | 支持卡拉OK、注释、样式等 |
| 使用场景 | 本地视频文件,简单字幕显示 | HTML5 视频,网络字幕,复杂字幕显示 |
| 是否嵌入视频 | 可嵌入视频文件 | 不可嵌入视频,只能用于网页<video>元素内使用 |
VTT(WebVTT)字幕格式不能直接嵌入到 MP4 文件中,但可以通过 HTML5 的 <track> 标签将 VTT 文件与 MP4 视频关联起来。在浏览器中打开 MP4 时,这些关联的字幕可以正常显示。
使用 VTT 字幕在浏览器中播放 MP4
在 HTML5 中,可以通过 <video> 元素加载 MP4 视频,并使用 <track> 元素将 VTT 字幕关联到该视频。
HTML 示例:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title></title>
</head>
<body>
<video controls width="600">
<source src="video.mp4" type="video/mp4">
<track src="subtitles.vtt" kind="subtitles" srclang="zh" label="简体中文">
Your browser does not support the video tag.
</video>
</body>
</html>
HTML 元素解释
<video>: 用于嵌入视频文件。controls 属性让用户可以控制视频播放(播放/暂停等)。<source>: 定义视频文件的路径和类型,在这里使用 MP4。<track>: 定义字幕文件,src 属性指向 VTT 文件的路径,kind="subtitles" 表示它是字幕,srclang 指定字幕的语言(zh 表示中文),label 给该字幕轨道一个描述性标签。
将 HTML 文件和相关的视频、字幕文件存放在同一目录下。然后,通过浏览器打开 HTML 文件(如 index.html),会看到视频播放器,点击播放时字幕会自动显示(如果播放器支持且用户开启字幕)。
大多数现代浏览器和视频播放器支持字幕切换。可以通过视频控制栏中的字幕按钮选择不同的字幕(如果有多个字幕轨道)。
VTT字幕注意事项
浏览器兼容性:几乎所有现代浏览器(如 Chrome、Firefox、Edge 等)都支持 <video> 元素和 WebVTT 字幕。只要 VTT 文件和 MP4 文件正确关联,浏览器中播放视频时应能显示字幕。
无法直接嵌入 MP4 文件:VTT 字幕文件不能像 SRT 或其他字幕格式那样直接嵌入到 MP4 文件中。MP4 文件本身不包含 VTT 字幕轨道。需要使用外部字幕文件并通过 HTML5 <track> 标签来关联。
VTT 字幕的样式:在浏览器中,WebVTT 字幕可以通过 CSS 进行一定的样式控制。如果需要定制字幕外观,可以通过 JavaScript 和 CSS 进一步修改样式。
ASS 字幕格式
ASS (Advanced SubStation Alpha) 是一种功能丰富的字幕格式,广泛用于动漫、卡拉OK字幕和其他需要复杂字幕特效的场景。支持丰富的样式控制,包括字体、颜色、位置、阴影和轮廓等。
下面是一个ass字幕示例。
[Script Info]
; Script generated by FFmpeg/Lavc60.27.100
ScriptType: v4.00+
PlayResX: 384
PlayResY: 288
ScaledBorderAndShadow: yes
YCbCr Matrix: None
[V4+ Styles]
Format: Name, Fontname, Fontsize, PrimaryColour, SecondaryColour, OutlineColour, BackColour, Bold, Italic, Underline, StrikeOut, ScaleX, ScaleY, Spacing, Angle, BorderStyle, Outline, Shadow, Alignment, MarginL, MarginR, MarginV, Encoding
Style: Default,黑体,16,&hffffff,&HFFFFFF,&h000000,&H0,0,0,0,0,100,100,0,0,1,1,0,2,10,10,10,1
[Events]
Format: Layer, Start, End, Style, Name, MarginL, MarginR, MarginV, Effect, Text
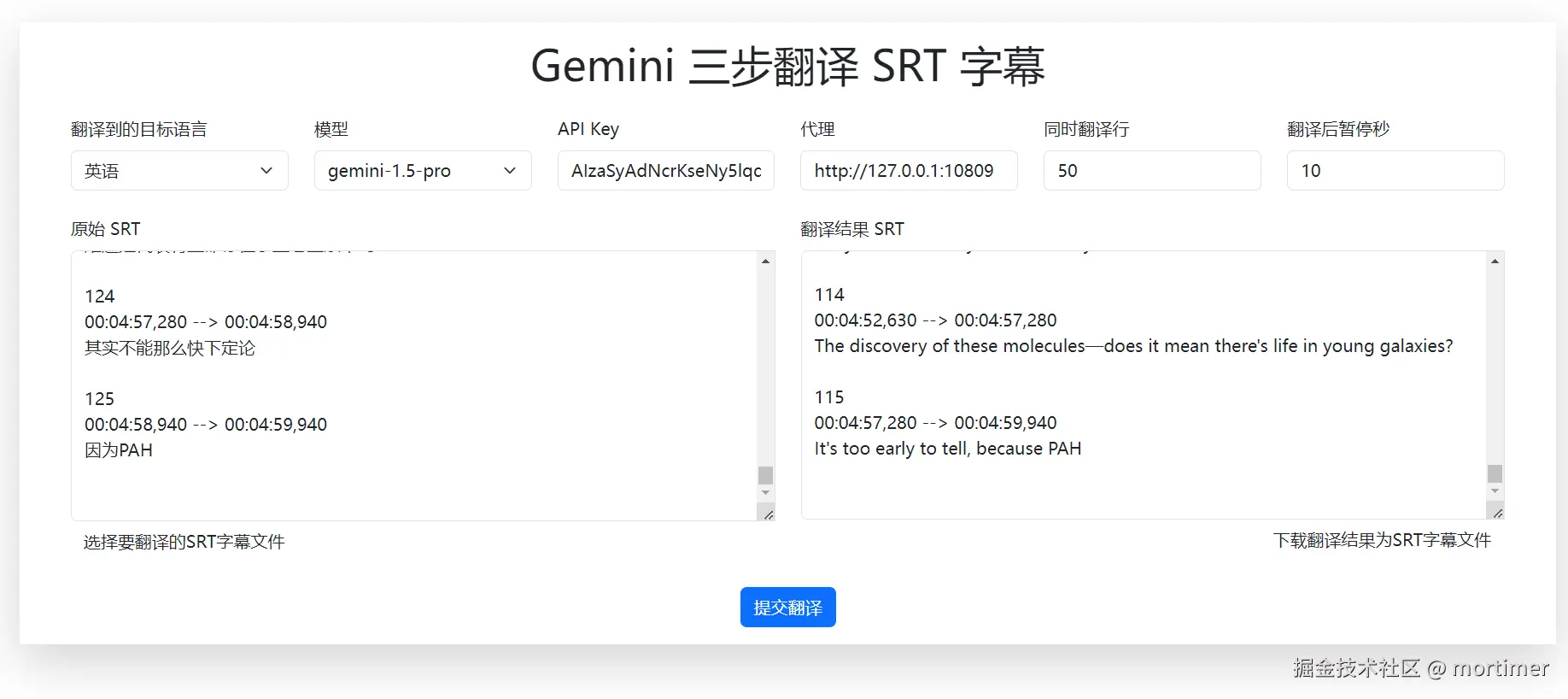
Dialogue: 0,0:00:01.95,0:00:04.93,Default,,0,0,0,,这是一个古老星系,
Dialogue: 0,0:00:05.42,0:00:08.92,Default,,0,0,0,,我们观测它已经有好几年,
Dialogue: 0,0:00:09.38,0:00:13.32,Default,,0,0,0,,韦伯望远镜最近传过来许多过去未发现过的照片.
ASS 字幕结构
一个标准的 ASS 字幕文件包含多个部分:
- [Script Info]:脚本的基本信息,如标题、原始字幕作者等。
- [V4+ Styles]:字幕样式定义,每种样式可以被不同的字幕行引用。
- [Events]:实际的字幕事件,定义了字幕的出现时间、消失时间和具体内容。
1. [Script Info] 部分
此部分包含字幕文件的元数据,定义了字幕的一些基本信息。
[Script Info]
Title: 字幕标题
Original Script: 字幕作者
ScriptType: v4.00+
PlayDepth: 0
PlayResX: 1920
PlayResY: 1080
ScaledBorderAndShadow: yes
YCbCr Matrix: None
Title: 字幕文件的标题。Original Script: 原始字幕的作者信息。ScriptType: 定义脚本版本,通常为 v4.00+。PlayResX 和 PlayResY: 定义视频的分辨率,表示字幕在该分辨率下的显示效果。PlayDepth: 视频的颜色深度,一般为 0。ScaledBorderAndShadow:指定是否将字幕的边框(Outline)和阴影(Shadow)按照屏幕分辨率进行缩放。yes是,no不缩放YCbCr Matrix:指定用于色彩转换的 YCbCr 矩阵。在视频处理和字幕渲染中,YCbCr 是一种色彩空间,通常用于视频编码和解码。这个设置可能影响字幕在不同色彩空间下的显示效果
2. [V4+ Styles] 部分
此部分定义字幕的样式,每个样式都可以通过字段控制字幕的字体、颜色、阴影等。格式如下:
[V4+ Styles]
Format: Name, Fontname, Fontsize, PrimaryColour, SecondaryColour, OutlineColour, BackColour, Bold, Italic, Underline, StrikeOut, ScaleX, ScaleY, Spacing, Angle, BorderStyle, Outline, Shadow, Alignment, MarginL, MarginR, MarginV, Encoding
Style: Default,Arial,20,&H00FFFFFF,&H0000FFFF,&H00000000,&H00000000,-1,0,0,0,100,100,0,0,1,1,0,2,10,10,20,1
字段解释:
Name:样式的名称,用于引用。
Fontname:字体名称。
Fontsize:字体大小。
PrimaryColour:主字幕颜色,表示字幕的主要颜色(通常是显示的文字颜色)。
- 示例:
&H00FFFFFF,白色字体。颜色值格式为 &HAABBGGRR,其中 AA 是透明度。
SecondaryColour:次字幕颜色,通常用于卡拉OK字幕的过渡颜色。
OutlineColour:轮廓颜色。
BackColour:背景颜色,通常用于 BorderStyle=3 的情况下(带背景框的字幕)。
Bold:粗体设置。
Italic:斜体设置。
Underline:下划线设置。
StrikeOut:删除线设置。
ScaleX:水平缩放比例,100 表示正常比例。
ScaleY:垂直缩放比例。
Spacing:字符间距。
Angle:字幕旋转角度。
BorderStyle:边框样式,定义字幕是否有轮廓或背景框。
- 示例:
1 表示有轮廓但无背景框,3 表示有背景框。
Outline:轮廓粗细。
Shadow:阴影深度。
Alignment:字幕对齐方式,使用 1-9 的数字定义不同的对齐位置。
对齐方式解释:
- 1:左下角
- 2:底部居中
- 3:右下角
- 4:左中
- 5:居中
- 6:右中
- 7:左上角
- 8:顶部居中
- 9:右上角
MarginL, MarginR, MarginV:左、右、垂直的边距,单位为像素。
- 示例:
10, 10, 20,表示左右边距为 10 像素,垂直边距为 20 像素。
Encoding:编码格式,1 表示 ANSI 编码,0 表示默认编码。
3. [Events] 部分
此部分定义实际的字幕事件,包括时间戳、字幕内容和使用的样式。
[Events]
Format: Layer, Start, End, Style, Name, MarginL, MarginR, MarginV, Effect, Text
Dialogue: 0,0:00:01.00,0:00:05.00,Default,,0,0,0,,这是第一句字幕
Dialogue: 0,0:00:06.00,0:00:10.00,Default,,0,0,0,,这是第二句字幕
字段解释:
Layer:层级,控制字幕的叠放顺序,数字越大层级越高。
Start:字幕开始时间,格式为 小时:分钟:秒.毫秒。
- 示例:
0:00:01.00,表示字幕从 1 秒处开始。
End:字幕结束时间。
- 示例:
0:00:05.00,表示字幕在 5 秒处结束。
Style:使用的字幕样式名称,引用在 [V4+ Styles] 中定义的样式。
- 示例:
Default,使用名称为 Default 的样式。
Name:可选字段,通常用于角色名标注。
MarginL, MarginR, MarginV:字幕的左、右、垂直边距,覆盖样式中定义的值。
Effect:字幕特效,通常用于卡拉OK字幕等。
Text:字幕的实际内容,可以使用 ASS 格式的控制符实现换行、特殊样式和定位等。
示例字幕事件
Dialogue: 0,0:00:01.00,0:00:05.00,Default,,0,0,0,,{\pos(960,540)}这是第一句字幕
{\pos(960,540)}:控制字幕显示在屏幕的特定位置(横向960像素,纵向540像素)。这是第一句字幕:实际显示的字幕文本。
ASS中颜色设置
以 &HAABBGGRR为例,&HAABBGGRR 是一个用于表示颜色的十六进制格式,其中包含了颜色的透明度和颜色本身的值。这个格式用于定义字幕的颜色属性,如 PrimaryColour、OutlineColour 和 BackColour。
含义如下:
AA: 透明度(Alpha 通道),表示颜色的透明度。BB: 蓝色分量(Blue)。GG: 绿色分量(Green)。RR: 红色分量(Red)。
具体的字节顺序为:Alpha(透明度)- Blue(蓝色)- Green(绿色)- Red(红色)。
如果不想使用透明度,可直接忽略掉AA位置的值,例如&HBBGGRR即可。
透明度和颜色值
实际颜色示例
完全透明的红色:
&H00FF0000
- 透明度
00(完全透明),颜色 FF0000(红色)。
完全不透明的绿色:
&HFF00FF00
- 透明度
FF(完全不透明),颜色 00FF00(绿色)。
&HAABBGGRR 中的 AA 部分控制透明度,BB, GG, RR 部分控制颜色。- 完全透明: 透明度
00,例如 &H00FF0000 表示完全透明的红色。 - 完全不透明: 透明度
FF,例如 &HFFFF0000 表示完全不透明的红色。