在faster-whisper语音识别渠道中,只有如下设置,才能取得最佳断句效果-!
语音识别的原理是将整个音频根据静音区间切割成若干小片段,每个片段可能是 1 秒、5 秒、10 秒或 20 秒等长度,然后将这些小片段转录为文字,再组合成字幕形式。
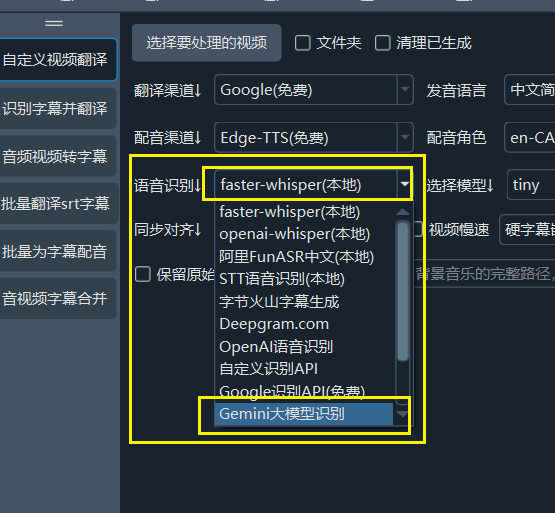
在使用 faster-whisper 模式 或 GeminiAI 作为语音识别渠道时,以下设置能取得相对较好的识别效果。
使用更大模型:首先当日是使用更大的模型,例如 tiny 模型太小,效果肯定不好,而 large-v2 模型效果会比它好数倍
优化设置: 点击
菜单--工具--高级选项
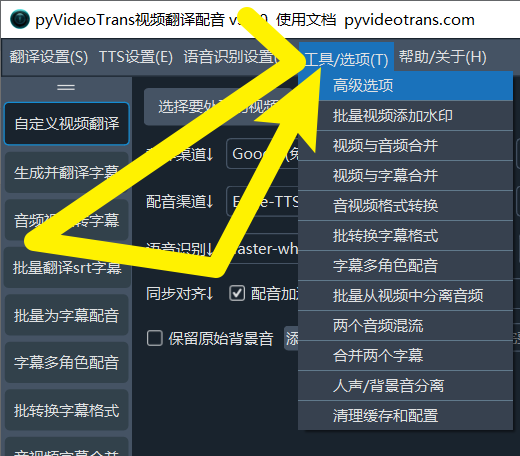
找到 faster/openai语音识别调整 部分,进行如下修改
- 语音阈值 设为
0.5 - 最短持续时间/毫秒 设为
0 - 最大语音持续时间/秒 设为
5 - 静音分隔毫秒 设为
140 - 语音填充 设为
0
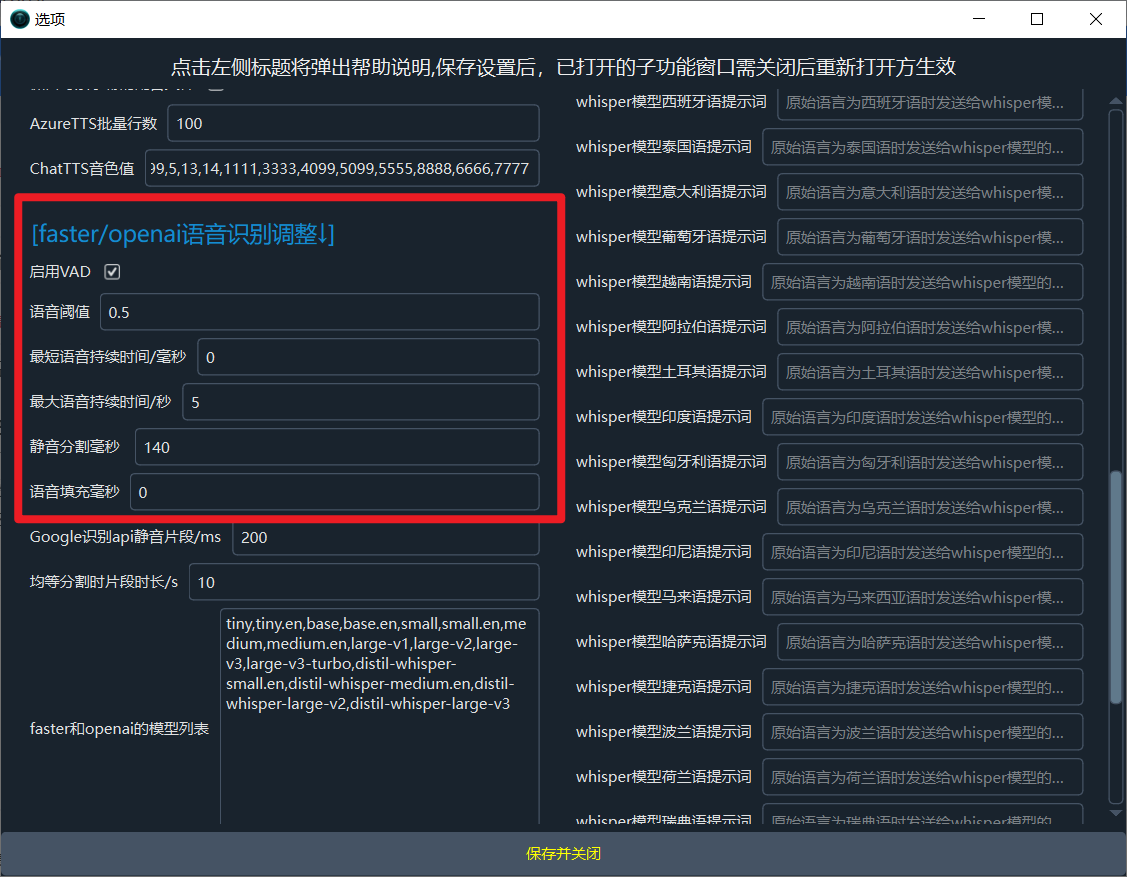
当然你也可以根据需要自行测试其他数值效果
edge-tts 降低 403 错误率(同样适用于其他配音渠道)
由于配音需要连接微软的 API,而该API有限流措施,403 错误无法完全避免。但可以通过以下调整减少错误发生:
找到 菜单 → 工具/选项 → 高级选项 → 配音调整 如下图
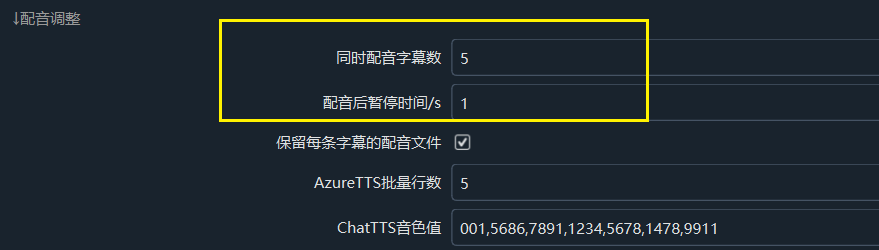
- 同时配音字幕数:建议设为 1。减少同时配音的字幕数量,可以降低因请求频率过高导致的错误。这一设置也适用于其他配音渠道。
- 配音后暂停时间/秒:例如设为 5,表示每完成一条字幕配音后暂停 5 秒再进行下一次配音。建议将此值设为 5 或更高,通过延长请求间隔降低错误率。