Achieving Optimal Sentence Segmentation in faster-whisper Speech Recognition Channel!
The principle of speech recognition involves segmenting the entire audio into several small clips based on silent intervals. Each clip might be 1 second, 5 seconds, 10 seconds, or 20 seconds long. These small clips are then transcribed into text and combined to form subtitles.
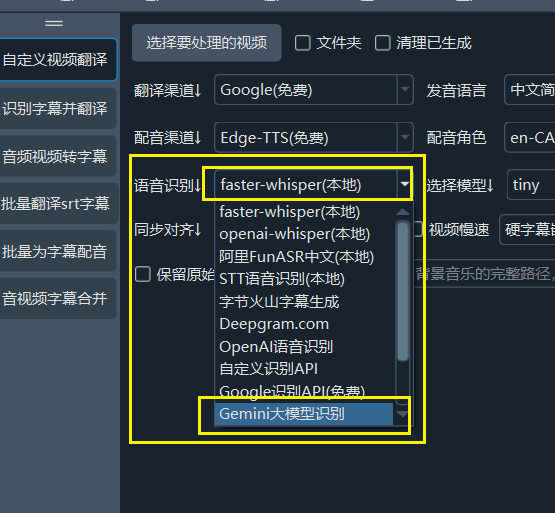
When using faster-whisper mode or GeminiAI as your speech recognition channel, the following settings can achieve relatively better recognition results.
Click `Menu -- Tools -- Advanced Options`
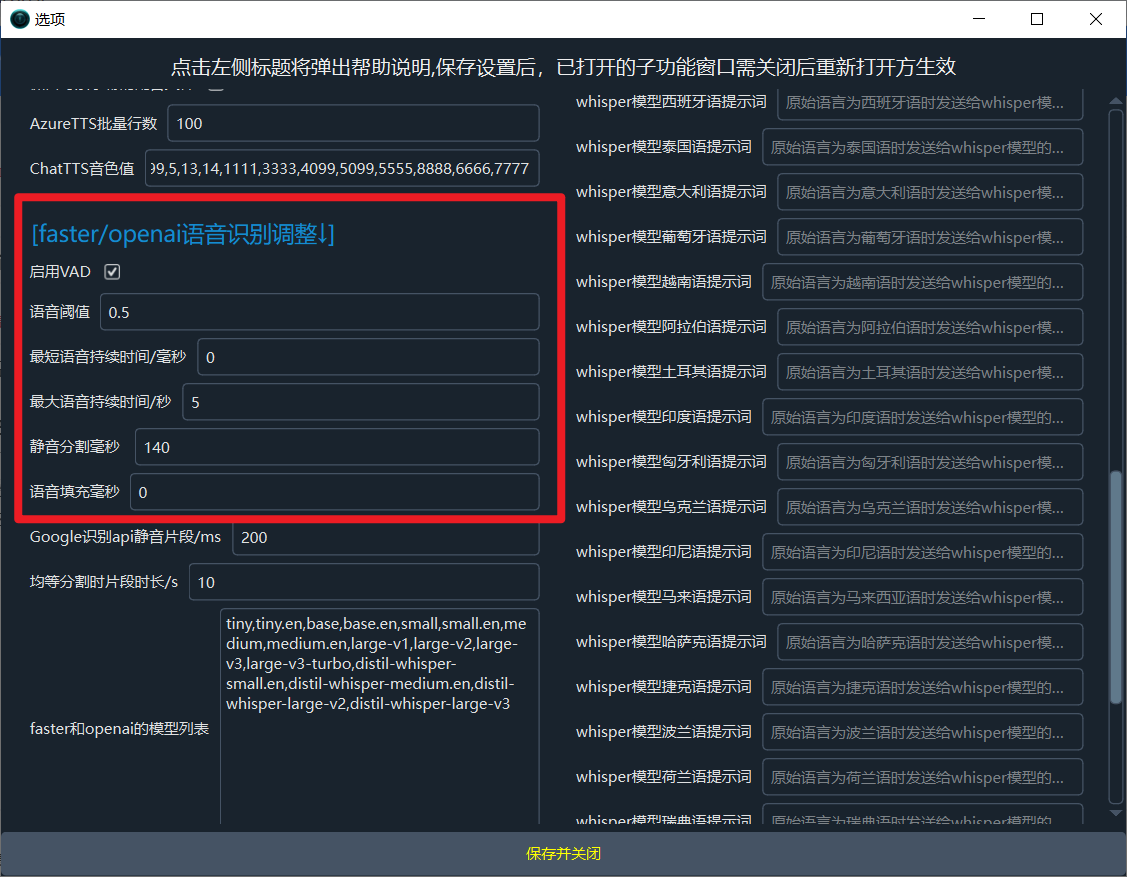
Locate the `faster/openai Speech Recognition Adjustments` section and make the following changes:
- Speech Threshold set to `0.5`
- Minimum Duration/ms set to `0`
- Maximum Speech Duration/s set to `5`
- Silence Separation/ms set to `140`
- Speech Padding set to `0`
Of course, you can also test other values according to your needs.
Reducing 403 Error Rate for edge-tts (Also Applicable to Other Dubbing Channels)
As dubbing requires connecting to Microsoft's API, 403 errors cannot be entirely avoided. However, you can reduce their occurrence with the following adjustments:
Navigate to `Menu → Tools/Options → Advanced Options → Dubbing Adjustments` as shown below:
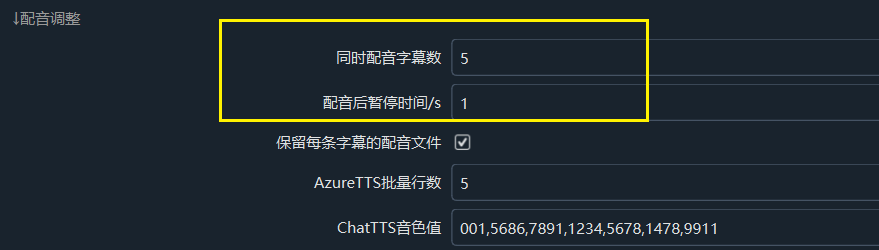
- Number of Concurrent Dubbing Subtitles: It is recommended to set this to `1`. Reducing the number of subtitles dubbed simultaneously can lower errors caused by excessive request frequency. This setting is also applicable to other dubbing channels.
- Pause Time After Dubbing/seconds: For instance, setting this to `5` means pausing for 5 seconds after each subtitle is dubbed before proceeding to the next. It is recommended to set this value to `5` or higher to reduce the error rate by extending the request interval.