Improving the Quality of AI-Translated Subtitles
When using AI to translate SRT subtitles, there are generally two approaches.
Approach 1: Translate the Complete Subtitle Format, Including Untranslated "Line Numbers" and "Timestamps."
How to enable: Select Send Complete Subtitle in the software.
The following is an example of sending the complete format:
1
00:00:01,950 --> 00:00:04,950
五老星系中发现了有机分子.
2
00:00:04,950 --> 00:00:07,902
我们离第三类接触还有多元。
3
00:00:07,902 --> 00:00:11,958
微波真是展开拍摄任务已经进来周年。Advantages: Maintains context, resulting in better translation quality.
Disadvantages: Besides wasting tokens, it may also lead to subtitle format errors during translation. The returned translation result may no longer be a valid SRT subtitle format. For example, English symbols , : may be incorrectly changed to Chinese symbols, or line numbers and time rows may be merged into one line, etc.
Approach 2: Only Send the Subtitle Text Content, and Then Replace the Corresponding Text in the Original Subtitle with the Translation Result.
How to enable: Uncheck Send Complete Subtitle in the software.
The following format only sends subtitle text:
五老星系中发现了有机分子.
我们离第三类接触还有多元。
微波真是展开拍摄任务已经进来周年。Advantages: Ensures that the translation result is always a valid SRT subtitle format.
Disadvantages: It is also obvious that translating subtitle text line by line cannot take context into account, and the translation quality is greatly reduced.
To solve this problem, the software supports translating multiple lines at a time, default 15 lines of subtitles, which can take into account the context to a certain extent.
However, this introduces a new problem: Different languages have different grammar rules and sentence structure orders. It is very likely that the original text is 15 lines, and after translation, it becomes 14 lines, 13 lines, etc., especially when the previous line and the following line are the same sentence in terms of grammatical structure.

If the translated result of 15 lines of original subtitles is no longer 15 lines, this will definitely cause subtitle confusion. To solve this problem, when the number of translated lines is inconsistent with the number of original subtitles, it is re-translated line by line to ensure that the number of subtitle lines before and after is completely consistent, and the context is discarded.
Note: The problem mentioned in the first method may occur, resulting in the result not being a legal SRT subtitle, which may cause parsing errors or loss of all content after the error. It is recommended to use this method only on sufficiently intelligent models, such as GPT-4o-mini or larger models. If it is a locally deployed model, it is not recommended to use this method. Limited by hardware resources, locally deployed models are generally small and not intelligent enough, and it is easier for the translation results to be in a chaotic format.
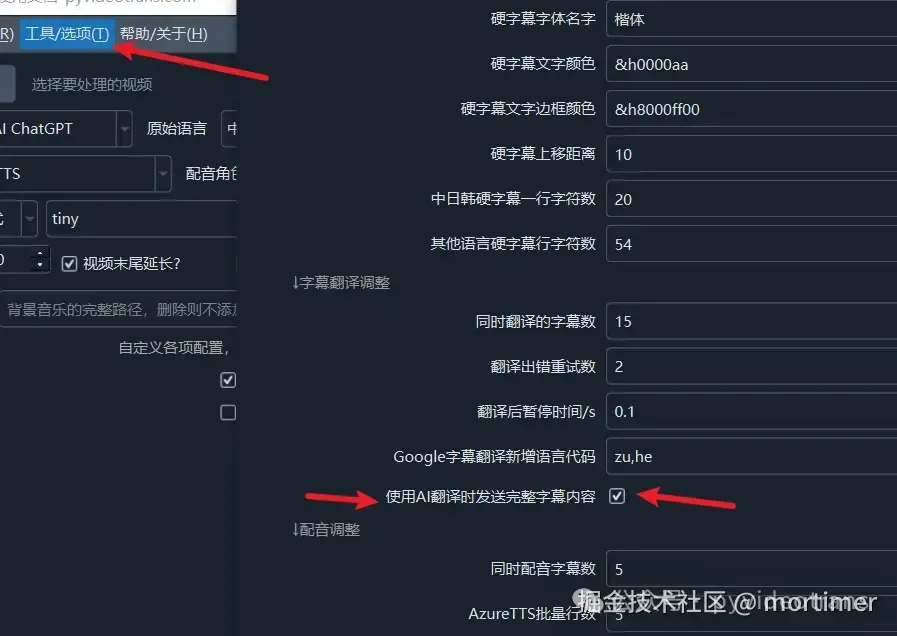
Enable the first translation method:
Menu--Tools/Options--Advanced Options--Subtitle Translation Area--Send Complete Subtitle when AI Translates
Adding a Glossary
You can add your own glossary to each prompt, similar to the following:
**During the translation process, be sure to use** the glossary I provide to translate the terms and maintain consistency. The specific glossary is as follows:
* Transformer -> Transformer
* Token -> Token
* LLM/Large Language Model -> Large Language Model
* Generative AI -> Generative AI
* One Health -> One Health
* Radiomics -> Radiomics
* OHHLEP -> OHHLEP
* STEM -> STEM
* SHAPE -> SHAPE
* Single-cell transcriptomics -> Single-cell transcriptomics
* Spatial transcriptomics -> Spatial transcriptomics