Custom Speech Recognition API
From version v3.56 onwards, the use of Gladia's speech recognition service is supported in this custom speech recognition channel. Please refer to this tutorial for specific usage methods
If you are not satisfied with the existing speech recognition methods, you can also customize your own speech recognition API. Simply fill in the relevant information in Menu - Speech Recognition Settings - Custom Speech Recognition API.
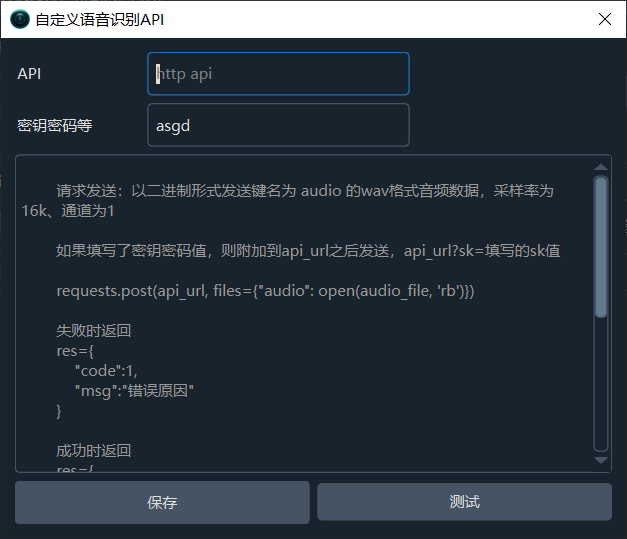
Fill in your API address, starting with http. The API address you enter will receive: WAV format audio data with the key name "audio", with a sampling rate of 16k and 1 channel. If your API has key verification, fill in the relevant password in the key box. This password will be appended to the API address and sent as sk=password.
requests.post(api_url, files={"audio": open(audio_file, 'rb')})
Your API needs to return data in JSON format. When a failure occurs, set the code to 1 and the message to the reason for the recognition failure.
Return on failure:
res={
"code":1,
"msg":"Reason for error"
}Return on success:
res={
"code":0,
"data":[
{
"text":"Subtitle text",
"time":'00:00:01,000 --> 00:00:06,500'
},
{
"text":"Subtitle text",
"time":'00:00:06,900 --> 00:00:12,200'
},
...multiple
]
}As shown below, if a key password value is filled in, it is appended to the api_url and sent, api_url?sk=the entered sk value
requests.post(api_url, files={"audio": open(audio_file, 'rb')})
#Return on failure
res={
"code":1,
"msg":"Reason for error"
}
#Return on success
res={
"code":0,
"data":[
{
"text":"Subtitle text",
"time":'00:00:01,000 --> 00:00:06,500'
},
{
"text":"Subtitle text",
"time":'00:00:06,900 --> 00:00:12,200'
},
]
}