The core principle of video translation software is to recognize text from the speech sounds in a video, then translate the text into the target language, dub the translated text, and finally embed the dubbing and text into the video.
As you can see, the first step is to recognize text from the speech in the video. The accuracy of this recognition directly affects subsequent translation and dubbing processes.
Faster Local Mode
Recommended for use, this mode is based on the open-source Whisper model from OpenAI. As the name suggests, it offers faster recognition speeds without sacrificing accuracy.
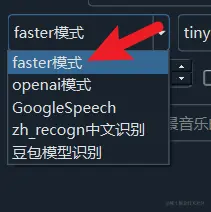
After selecting the Faster mode, you can choose the model to use on the right. The default is the built-in tiny model, which is the smallest model and also the least accurate.
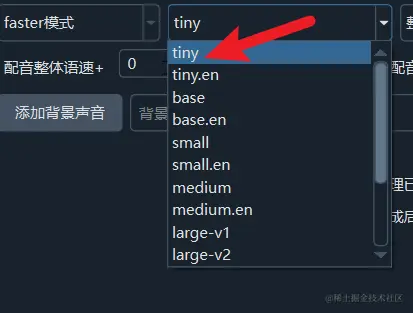
The model sizes increase from tiny to base to small to medium to large, and the recognition accuracy also increases accordingly.
For Chinese videos, it is recommended to select at least the medium model. Model download addresses are available at https://github.com/jianchang512/stt/releases/0.0
Models with the .en suffix and models starting with distil are only for English videos.
To the right of the model, there is also an Overall Recognition drop-down box. The drop-down menu displays Equal Division. Generally, you can select Overall Recognition unless you have special needs. If you need to divide the audio into segments of equal duration, such as wanting each subtitle to be 10 seconds long, you can select equal division. Then set the segment duration in seconds in Menu -- Tools/Advanced Settings -- Advanced Settings -- VAD parameters section.
To speed up the task, on Windows and Linux, if you have an NVIDIA graphics card, you can configure and install the CUDA and cuDNN environment and then enable CUDA acceleration, which can significantly improve execution speed.
View CUDA and cuDNN installation tutorial
Automatic Language Detection
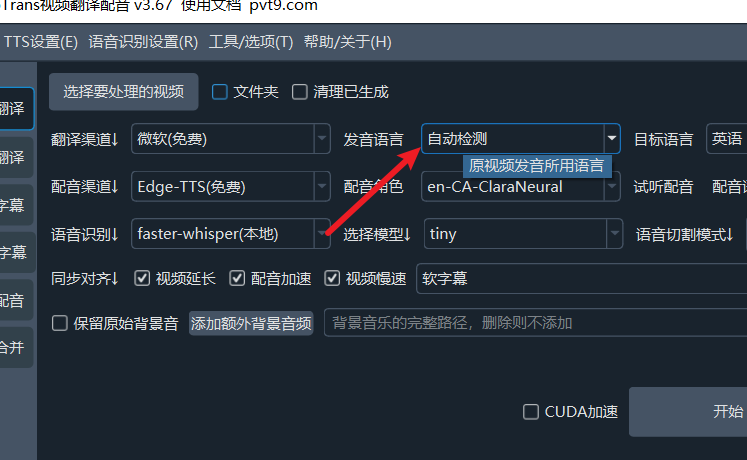
In version v2.59 and later, the original language drop-down box adds an "Automatic Detection" option. When you don't know what language it is, or the language is not among the supported 24 languages, you can select the "Automatic Detection" option, and the program will try to automatically identify the spoken language.
Of course, if possible, try to avoid using this option, especially when there is no clear speech in the first 30 seconds of the video, because the principle of automatic detection is to use the first 30 seconds of audio clips to make a judgment, in order to set the language used for the entire video. Another point to note: Some languages with similar pronunciations but different writing methods cannot be accurately identified and may be identified as any one of them. For example, Chinese videos may be randomly identified as Simplified or Traditional.