This is a webui and API project for Kokoro TTS, supporting text-to-speech in 8 languages: Chinese, English, Japanese, French, Italian, Portuguese, Spanish, and Hindi.
Project Address: https://github.com/jianchang512/kokoro-uiapi
Web Interface
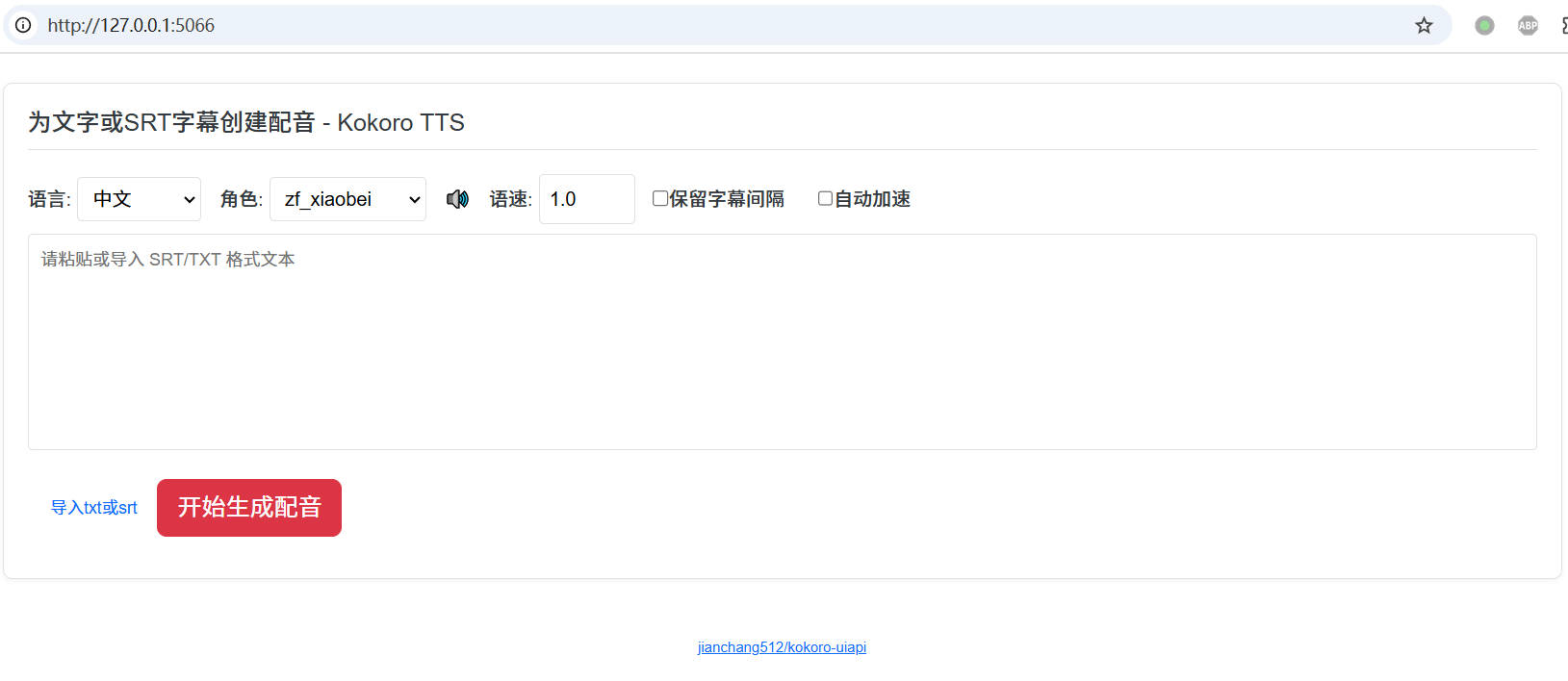
Default UI address after startup: http://127.0.0.1:5066
- Supports text-to-speech and SRT subtitle dubbing.
- Supports online listening and downloading.
- Supports subtitle alignment.
Installation
Windows
For Windows 10/11, you can directly download the integrated package and double-click start.bat to start. If you need GPU acceleration, please ensure you have an NVIDIA graphics card and CUDA 12 installed.
GitHub Download Address: https://github.com/jianchang512/kokoro-uiapi/releases/v0.1
Linux/MacOS
First, ensure that your system has Python 3.8+ installed (recommended 3.10-3.11).
On Linux, use
apt install ffmpegoryum install ffmpegto pre-install ffmpeg.On MacOS, use
brew install ffmpegto install ffmpeg.
Clone the source code:
git clone https://github.com/jianchang512/kokoro-uiapiCreate and activate a virtual environment:
cd kokoro-uiapi python3 -m venv venv . venv/bin/activateInstall dependencies:
pip3 install -r requirements.txtStart the application:
python3 app.py
Using in pyVideoTrans
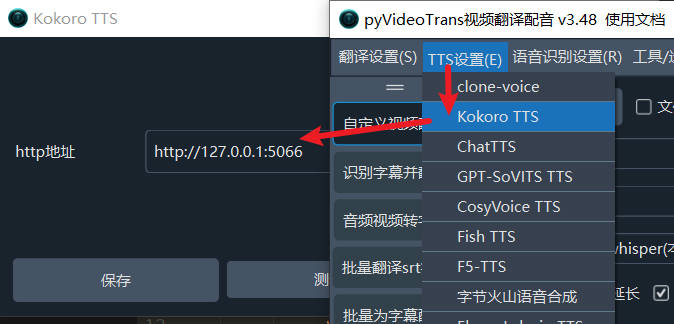
- First, start this project. For the Windows integrated package, double-click
start.bat. For source code installation, executepython3 app.py. - Upgrade pyVideoTrans to v3.48+. Open Menu -- TTS Settings -- Kokoro TTS -- Enter
http://127.0.0.1:5066for the HTTP address.
OpenAI API Compatibility
The API is compatible with OpenAI TTS.
Default API address after startup: http://127.0.0.1:5066/v1/audio/speech
Request Method: POST Request Data: application/json
{
input: The text to be synthesized,
voice: The voice actor,
speed: Speech rate (default 1.0)
}Successful response returns MP3 audio data.
OpenAI SDK Usage Example
from openai import OpenAI
client = OpenAI(
api_key='123456',
base_url='http://127.0.0.1:5066/v1'
)
try:
response = client.audio.speech.create(
model='tts-1',
input='Hello, dear friends',
voice='zf_xiaobei',
response_format='mp3',
speed=1.0
)
with open('./test_openai.mp3', 'wb') as f:
f.write(response.content)
print("MP3 file saved successfully to test_openai.mp3")
except Exception as e:
print(f"An error occurred: {e}")Voice Role List
English voice roles:
af_alloy
af_aoede
af_bella
af_jessica
af_kore
af_nicole
af_nova
af_river
af_sarah
af_sky
am_adam
am_echo
am_eric
am_fenrir
am_liam
am_michael
am_onyx
am_puck
am_santa
bf_alice
bf_emma
bf_isabella
bf_lily
bm_daniel
bm_fable
bm_george
bm_lewisChinese voice roles:
zf_xiaobei
zf_xiaoni
zf_xiaoxiao
zf_xiaoyi
zm_yunjian
zm_yunxi
zm_yunxia
zm_yunyangJapanese voice roles:
jf_alpha
jf_gongitsune
jf_nezumi
jf_tebukuro
jm_kumoFrench voice roles: ff_siwis
Italian voice roles: if_sara,im_nicola
Hindi voice roles: hf_alpha,hf_beta,hm_omega,hm_psi
Spanish voice roles: ef_dora,em_alex,em_santa
Portuguese voice roles: pf_dora,pm_alex,pm_santa
Proxy VPN
Source code deployment requires downloading voice pt files from huggingface.co. You need to set up a global proxy or system proxy in advance to ensure access.
You can also download the model in advance and extract it to the directory where app.py is located.
Model download address: https://github.com/jianchang512/kokoro-uiapi/releases/download/v0.1/moxing--jieya--dao--app.py--mulu.7z