Why Are Recognized Subtitles Uneven and Chaotic? - How to Optimize and Adjust?
In video translation, automatically generated subtitles from the speech recognition stage often have unsatisfactory results. Either the subtitles are too long, almost filling the screen, or they only display two or three characters, appearing fragmented. Why does this happen?
Speech Recognition's Sentence Segmentation Standards
Speech Recognition:
When converting human speech to text subtitles, the process usually cuts sentences based on silent intervals. Generally, the duration of silent segments is set between 200 and 500 milliseconds. For example, if set to 250 milliseconds, the program considers the end of a sentence when it detects silence lasting for 250 milliseconds. At this point, a subtitle is generated from the previous end point to here.
Factors Affecting Subtitle Quality
- Speaking Speed
If the speaking speed in the audio is very fast with almost no pauses, or the pauses are less than 250 milliseconds, the segmented subtitles will be very long, possibly lasting ten or even dozens of seconds, filling the screen when embedded in the video.

- Irregular Pauses:
Conversely, if there are unwarranted pauses during speech, such as pausing several times in the middle of a coherent sentence, the segmented subtitles will be very fragmented, possibly displaying only a few words per subtitle.

- Background Noise
Background noise or music can also interfere with the judgment of silent intervals, leading to inaccurate recognition.
- Pronunciation Clarity: This is obvious. When the pronunciation is unclear, even humans cannot understand it.
How to Address These Issues?
- Reduce Background Noise:
If the background noise is significant, you can separate the human voice from the background sound before recognition to remove interference and improve recognition accuracy.
- Use a Large Speech Recognition Model:
If computer performance allows, try to use a large model for recognition, such as large-v2 or large-v3-turbo.
- Adjust Silent Segment Duration:
The software defaults to setting the silent segment to 200 milliseconds. Depending on the specific situation of the audio and video, you can adjust this value. If the video you want to recognize has a fast speaking speed, you can reduce it to 100 milliseconds; if there are many pauses, you can increase it to 300 or 500 milliseconds. To set this, open the Tools/Options menu, then select Advanced Options, and modify the minimum silent segment value in the faster/openai speech recognition adjustment section.
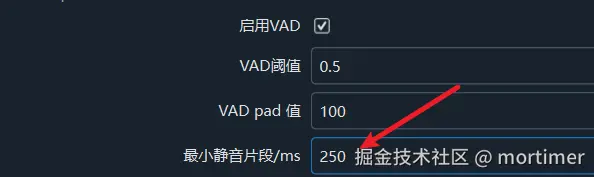
- Set Maximum Subtitle Duration:
You can set the maximum duration for subtitles, and subtitles exceeding this duration will be forcibly split. This setting is also in the Advanced Options.
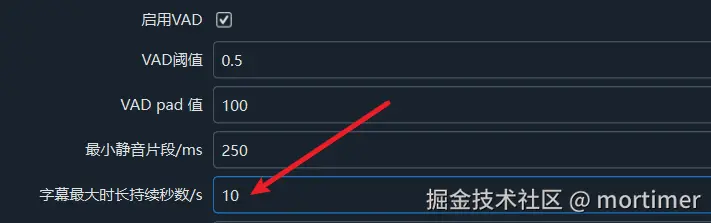
As shown in the figure, subtitles longer than 10 seconds will be re-cut.
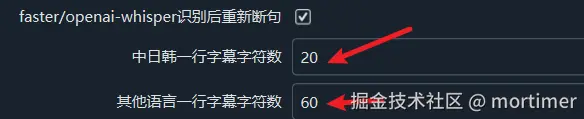
- Set the Maximum Number of Characters per Subtitle Line:
You can set the maximum number of characters per subtitle line, and subtitles exceeding the character limit will automatically wrap or split.
- Enable LLM Re-segmentation: After enabling this option, combined with settings 4 and 5 mentioned above, the program will automatically re-segment sentences.
After the above 3, 4, 5, and 6 settings, the program will first generate subtitles based on silent intervals. When encountering overly long subtitles or too many characters, the program will split the subtitles by re-segmenting sentences.