Speech recognition, also known as Automatic Speech Recognition (ASR), is the process of converting human speech in audio and video into text. It's the foundational step in video translation, and critically influences the quality of the subsequent dubbing and subtitling processes.
Currently, the software primarily supports offline, local recognition using two methods: faster-whisper (local) and openai-whisper (local).
These two methods are quite similar. Essentially, faster-whisper is a re-engineered and optimized version of openai-whisper. While the recognition accuracy is generally consistent between the two, faster-whisper offers faster processing speeds. However, utilizing CUDA acceleration with faster-whisper places more stringent requirements on environment configuration.
faster-whisper Local Recognition Mode
This mode is the software's default and recommended option due to its faster speed and higher efficiency.
Within this mode, model sizes range from smallest to largest: tiny -> base -> small -> medium -> large-v1 -> large-v3.
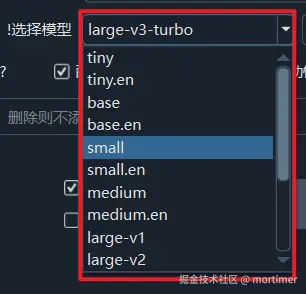
Model sizes progressively increase from 60MB to 2.7G. Consequently, the required memory, VRAM (video RAM), and CPU/GPU consumption also increase. If available VRAM is below 10GB, using large-v3 is not recommended, as it may lead to crashes or freezes.
From tiny to large-v3, the recognition accuracy improves with increasing model size and resource consumption. Models like tiny/base/small are considered micro-models, offering fast recognition speeds and low resource usage, but with lower accuracy.
medium is an intermediate model. If you need to recognize videos with Chinese audio, it's recommended to use at least the medium model or larger for better results.
If your CPU is powerful and you have ample memory, even without CUDA acceleration, you can opt for the large-v1/v2 models. These models offer significantly improved accuracy compared to the smaller models, although the recognition speed will be slower.
large-v3 demands substantial resources. Unless you have a high-performance computer, its use is not recommended. Consider using large-v3-turbo as a replacement; it offers similar accuracy with faster processing and lower resource consumption.
Models with names ending in
.enor starting withdistilare specifically designed for English audio and should not be used for videos in other languages.
openai-whisper Local Recognition Mode
The models available in this mode are essentially the same as in faster-whisper, ranging from small to large: tiny -> base -> small -> medium -> large-v1 -> large-v3. The usage considerations are also consistent. tiny/base/small are micro-models, and large-v1/v2/v3 are large models.
Summary and Selection Guide
- Prioritize using faster-whisper local mode unless you encounter persistent environment errors when attempting CUDA acceleration. In such cases, you can use openai-whisper local mode.
- Regardless of the chosen mode, for recognizing videos with Chinese audio, it is highly recommended to use at least the medium model, or at minimum small. For English audio, at least small is recommended. If your computer resources are sufficient, consider using large-v3-turbo for optimal results.
- Models ending in
.enor starting withdistilare designed exclusively for English audio.