VAD Parameter Tuning in Speech Recognition
Subtitles generated during the speech recognition phase of video translation can sometimes be very long, lasting tens of seconds or even minutes, while other times they are very short, less than 1 second. These can all be optimized by adjusting the VAD parameters.
What is VAD?
Silero VAD is an efficient Voice Activity Detection (VAD) tool that identifies whether audio contains speech and separates speech segments from silence or noise. Silero VAD can be used in conjunction with other speech recognition libraries (such as Whisper) to detect and segment speech segments before or after speech recognition, optimizing recognition performance.

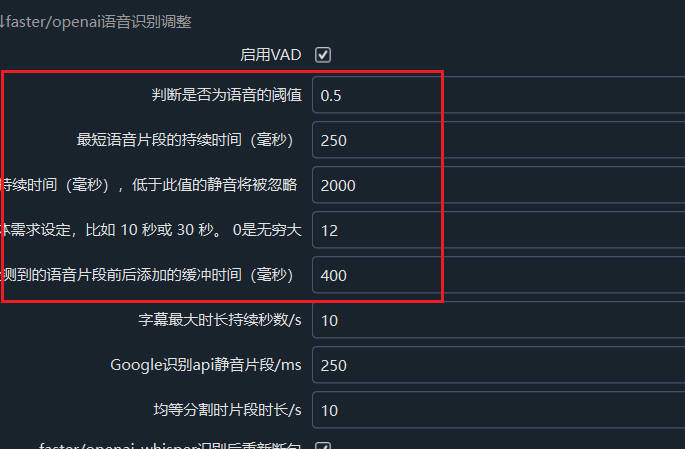
In faster-whisper, VAD is used by default for voice analysis and segmentation. The following four parameters are mainly involved in controlling and adjusting the segmentation recognition effect. These parameters are used to control the judgment and segmentation of speech and silence. Here are detailed explanations and setting suggestions for each parameter:
threshold
Meaning: Represents the probability threshold for speech. Silero VAD outputs the speech probability of each audio segment. Probabilities above this value are considered speech (SPEECH), and probabilities below this value are considered silence or background noise.
Setting Suggestion: The default value is 0.5, which is suitable for most cases. However, for different datasets, you can adjust this value to more accurately distinguish between speech and noise. If you find too many false positives (noise being identified as speech), you can try increasing it to 0.6 or 0.7; if too many speech segments are lost, you can lower it to 0.3 or 0.4.
min_speech_duration_ms (Minimum Speech Duration, in milliseconds)
Meaning: If the length of a detected speech segment is less than this value, the speech segment will be discarded. The purpose is to remove some short non-speech sounds or noise.
Setting Suggestion: The default value is 250 milliseconds, which is suitable for most scenarios. You can adjust it as needed. If short speech segments are easily misjudged as noise, you can increase this value, for example, set it to 500 milliseconds.
max_speech_duration_s (Maximum Speech Duration, in seconds)
Meaning: The maximum length of a single speech segment. If a speech segment exceeds this duration, the system will attempt to split it at a silent point longer than 100 milliseconds. If no silent point is found, the segment will be forcefully split before this duration to avoid excessively long continuous segments.
Setting Suggestion: The default is infinity (no limit). If you need to process long speech segments, you can keep the default value; however, if you want to control the segment length, such as for processing dialogues or segmented output, you can set it according to your specific needs, such as 10 seconds or 30 seconds.
min_silence_duration_ms (Minimum Silence Duration, in milliseconds)
Meaning: The silence time to wait after speech is detected. The speech segment is only split if the silence duration exceeds this value.
Setting Suggestion: The default value is 2000 milliseconds (2 seconds). If you want to detect and split speech segments more quickly, you can reduce this value, for example, set it to 500 milliseconds; if you want to split more loosely, you can increase it.
speech_pad_ms (Speech Padding Time, in milliseconds)
Meaning: The padding time added before and after the detected speech segment to avoid cutting the speech segment too tightly, which may cut off some edge speech.
Setting Suggestion: The default value is 400 milliseconds. If you find that the cut speech segment is missing parts, you can increase this value, such as 500 milliseconds or 800 milliseconds. Conversely, if the speech segment is too long or contains too many invalid parts, you can reduce this value.
The specific settings of these parameters need to be optimized according to the speech dataset and application scenarios you are using. Reasonable configuration can significantly improve the performance of VAD.
The above parameters can be modified and adjusted in Menu -- Tools/Options -- Advanced Options -- faster/openai You can also select
faster-whisper localafter speech recognition in the main interface, and click the "Speech Recognition" text on the left to display the modification text box for these parameters below.
Summary:
threshold: Can be adjusted according to the dataset, the default value of 0.5 is more general.
min_speech_duration_ms and min_silence_duration_ms: Determine the length of the speech segment and the sensitivity of silence segmentation, fine-tune according to the application scenario.
max_speech_duration_s: Prevents unreasonable growth of long speech segments and is usually set according to specific applications.
speech_pad_ms: Adds a buffer to the speech segment to avoid over-cutting the segment. The specific value selection depends on your audio data and the needs of speech segmentation.
The cleaner and clearer the sound is without noise, the better the recognition effect. Even the most carefully modulated parameters are not as effective as a clean background sound.